
728x90
2023.01.18
3-1 3주차 설치
파이썬(윈도우 다운로드)
https://www.python.org/ftp/python/3.8.6/python-3.8.6-amd64.exe

(5주차를 위한)
gitbash 다운로드
Git
git-scm.com
3-2 연습 겸 복습 - 스파르타피디아에 OpenAPI 붙여보기
- 스파르타피디아 API(GET)
http://spartacodingclub.shop/web/api/movie
- 로딩 후 바로실행
$(document).ready(function(){
listing();
});
function listing() {
console.log('화면 로딩 후 잘 실행되었습니다');
}
- 반복 출력
let star_image = '⭐'.repeat(star) // star만큼 '⭐' 반복
3-3 파이썬 시작하기
- 파이썬 프로젝트 생성
3-4 파이썬 기초공부
파이썬은 매우 직관적인 언어 (들여쓰기가 아주 중요!!)
- 변수 선언
// let 선언할 필요 없음
a = 1
b = 2
- 함수
def f(x):
return x
- 조건문
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
- 반복문 (리스트와 함께 쓰임)
fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)
3-5 파이썬 패키지 설치하기
패키지 설치 = 외부 라이브러리 설치
(가상 환경 / 프로젝트별로 라이브러리 설정이 가능하다~!!)
3-6 패키지 사용해보기
Requests 라이브러리 사용해보기
- 모든 구의 IDEX_MVL 값 가져오기
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows:
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
print(gu_name, gu_mise)
3-7 웹스크래핑(크롤링) 기초
- 제목을 쉽게 찾게 해주는 라이브러리 beautyfulsoup 패키지 추가 설치
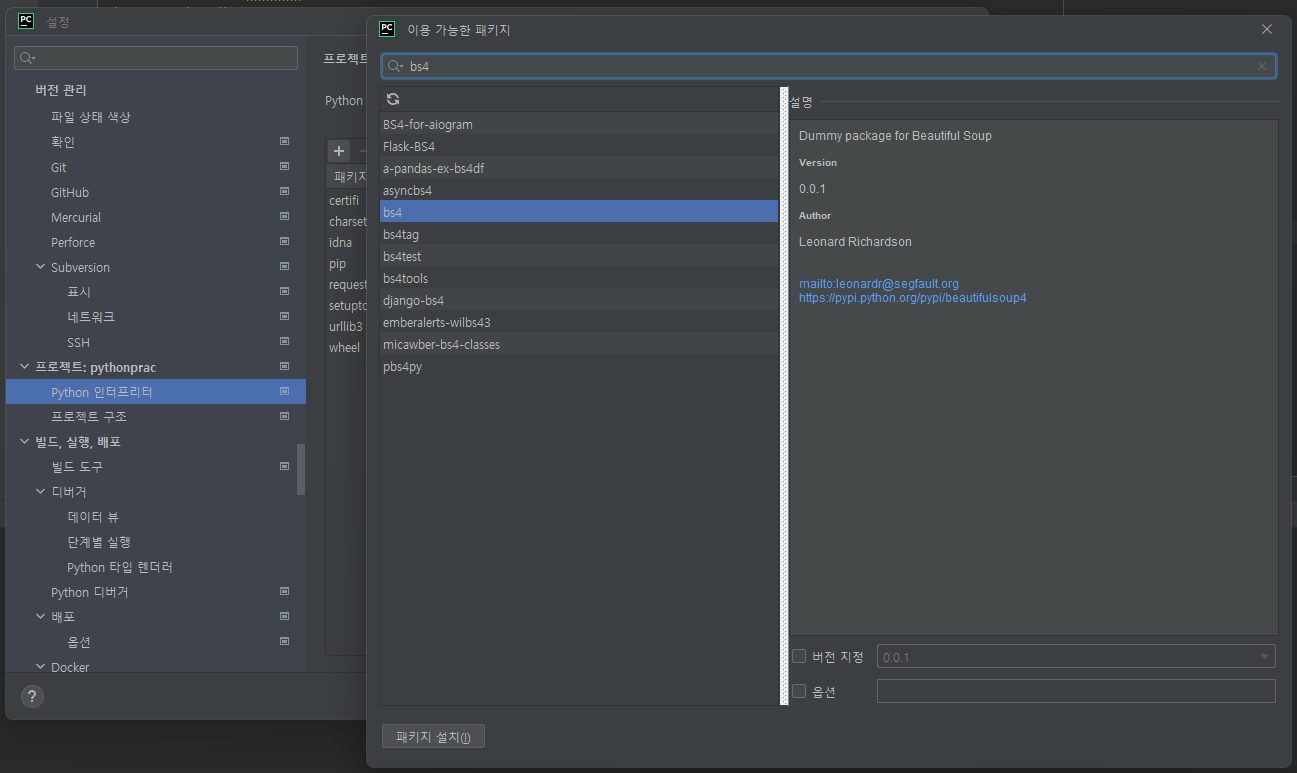
- 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
- 영화 제목 받아오기
네이버 영화 랭킹 사이트를 크롤링 해보았다
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com

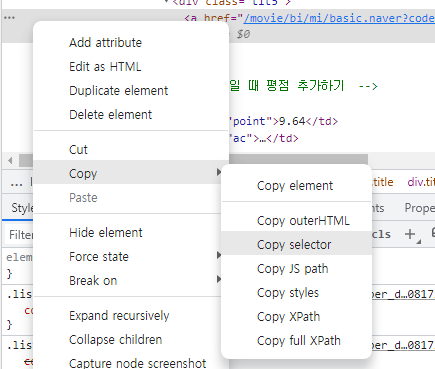
// ↓ 이곳에 복사한 위치를 붙여넣는다
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
// 태그 안의 텍스트를 찍고 싶을 땐 → 태그.text
// 태그 안의 속성을 찍고 싶을 땐 → 태그['속성']
print(title)
print(title.text)
print(title['href'])<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a>
밥정
/movie/bi/mi/basic.naver?code=186114
// 순으로 출력되었다.
- 영화 제목 전체 받아오기 (반복문)
movies = soup.select('#old_content > table > tbody > tr')
print(movies)
for movie in movies:
a = movie.select_one('td.title > div > a')
# 가로선은 none으로 나오므로 제외했다
if a is not None:
print(a.text)
- select 정의된 방법
```python
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
```
3-8 Quiz_웹스크래핑(크롤링) 연습
- 순위, 제목, 평점 가져오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
name = movie.select_one('td.title > div > a')
if name is not None:
title = name.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)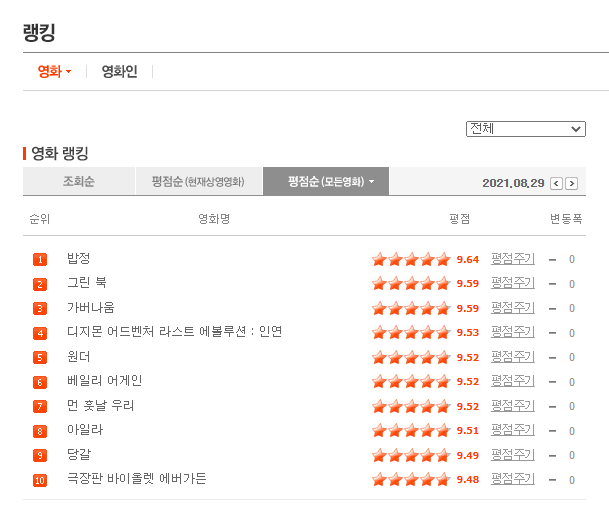

728x90
'개발일기 > 웹 종합' 카테고리의 다른 글
| mongoDB 연결하기 (1) | 2023.01.19 |
|---|---|
| 크롤링 연습 (기상청 홈페이지) (0) | 2023.01.18 |
| Ajax (0) | 2023.01.14 |
| JQuery (0) | 2023.01.14 |
| 부트스트랩, Javascript 사용 (0) | 2023.01.14 |



